School of Information Sciences
University of Illinois at Urbana-Champaign
Computer Science and Engineering
Hong Kong University of Science and Technology
Research Scientist
Intel Labs
School of Information Sciences
University of Illinois at Urbana-Champaign
Thirty-Ninth Annual Conference on Neural Information Processing Systems (NeurIPS 2025)
*Corresponding Author
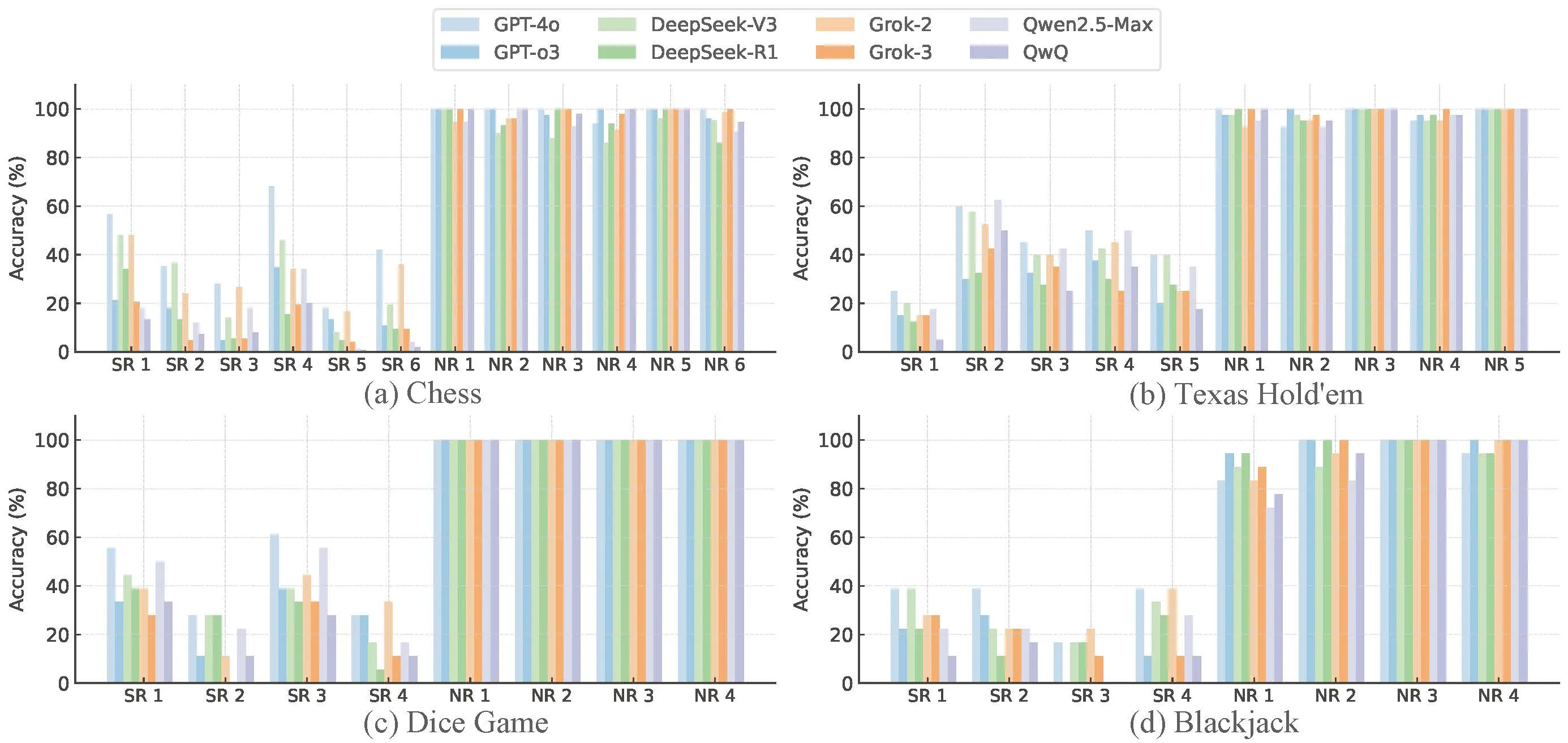
Large Language Models (LLMs) have shown remarkable progress across domains, yet their ability to perform inductive reasoning—inferring latent rules from sparse examples—remains limited. It is often assumed that chain-of-thought (CoT) prompting, as used in Large Reasoning Models (LRMs), enhances such reasoning. We investigate this assumption with creating four controlled, diagnostic game-based tasks—chess, Texas Hold’em, dice games, and blackjack—with hidden human-defined rules. We find that CoT reasoning can degrade inductive performance, with LRMs often underperforming their non-reasoning counterparts.
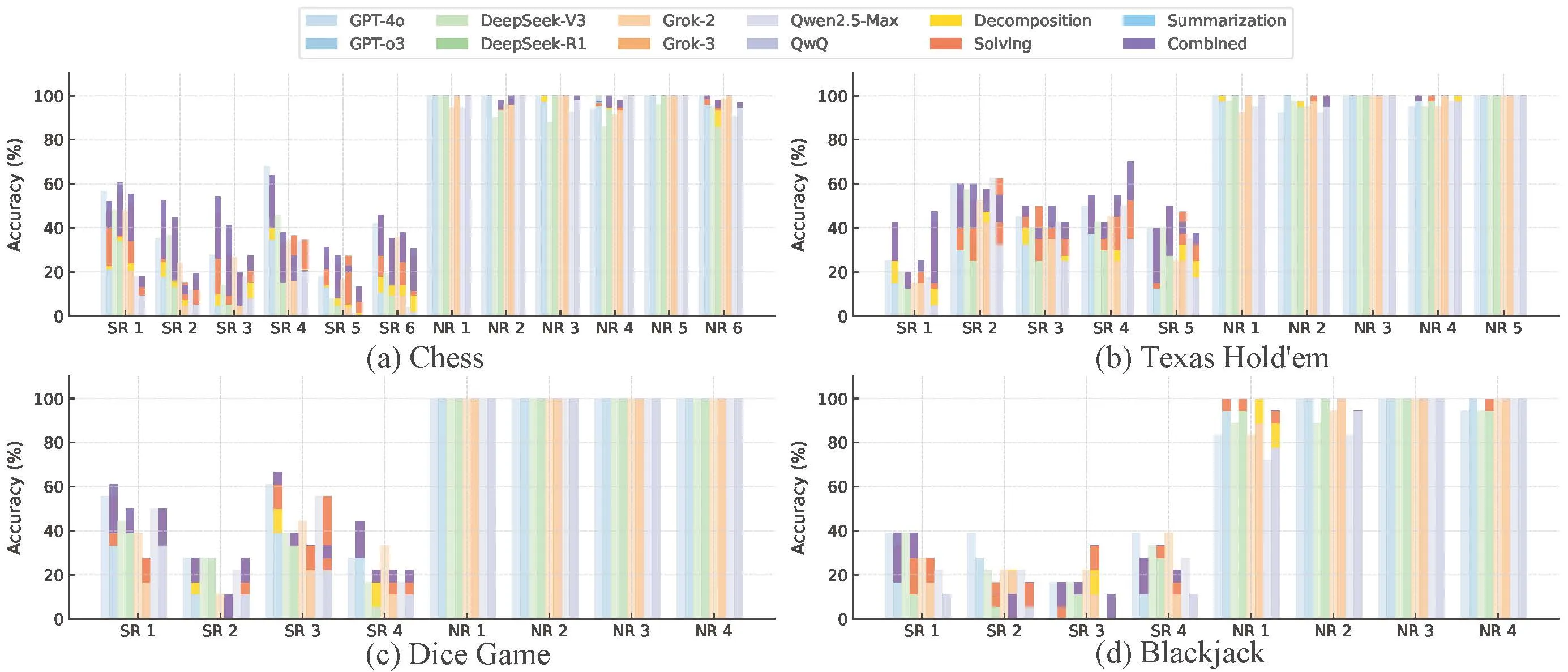
To explain this, we present a theoretical framework that reveals how reasoning steps can amplify error through three failure modes: incorrect sub-task decomposition, incorrect sub-task solving, and incorrect final answer summarization. Based on our theoretical and empirical analysis, we introduce structured interventions that adapt CoT generation according to our identified failure types. These interventions improve inductive accuracy without retraining. Our findings suggest that effective (CoT) reasoning depends not only on taking more steps but also on ensuring those steps are well-structured.
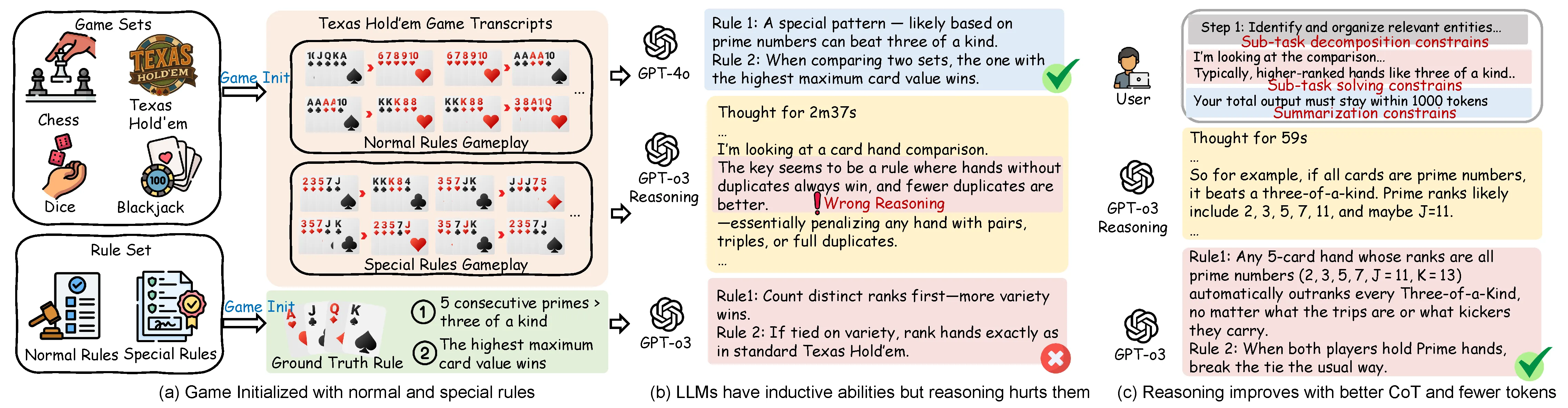
Examples illustrating inductive reasoning on gameplay transcripts. (a) Games begin with both Normal and hidden Special Rules, requiring models to infer latent constraints from observed plays. (b) LLMs can induce rules like card legality and win conditions without explicit guidance, but LRMs such as GPT-o3 may underperform due to misaligned or noisy reasoning. (c) Reasoning improves when guided at the decomposition, solving, and summarization stages.
The presentation video on the left explains the problem addressed, our methodology, and key outcomes, helping viewers understand the broader impact of our work. On the right, the poster offers a visual summary of major findings and innovations, designed to capture the core essence of our research at a glance.



Join our community on Slack to discuss ideas, ask questions, and collaborate with new friends.
Join Slack
Provide us feedback by sharing insights or suggesting additional resources related to our study.
Fill This Form
The Trustworthy ML Initiative (TrustML) addresses challenges in responsible ML by providing resources, showcasing early career researchers, fostering discussions and building a community.
More Info @article{jin2025reasoning,
title={Reasoning Can Hurt the Inductive Abilities of Large Language Models},
author={Jin, Haibo and Zhang, Peiyan and Luo, Man and Wang, Haohan},
journal={arXiv preprint arXiv:2505.24225},
year={2025}
}